Google’s Doodle on January 9 honored Har Gobind Khorana, a Nobel laureate whose work with DNA, RNA, and protein synthesis was seminal to deciphering the genetic code. Did anyone besides us (shout out to our own Eli Kosminsky!) notice that, midway through the day, the cartoon changed?

Google Doodle in the morning…


The same Doodle at night!
A comparison shows that the letters vanished from the paired strands draped across the doodle, leaving the flag-like bases letterless. A look at the letters depicted in the original doodle’s strands shows the letter “U,” for the base uracil, on both sides, making the drawing look like two paired strands of RNA. It’s the paired RNA strands that was the problem, we surmise. RNA, unlike DNA, comprises a single strand of nucleotide bases or “letters,” not a double strand (which, in the case of DNA, twists into the classic double-helix shape). By labeling both strands of the molecule with RNA letters, the doodle effectively depicted RNA as an extended double-stranded molecule, which is incorrect.
Removing the letters allowed the doodle to be interpreted correctly as showing the transcription of RNA from DNA, which is not only biologically relevant, it’s also a critical component of Khorana’s work. In fact, part of Khorana’s approach involved assiduously avoiding the now-classic behavior of some RNA sequences that might have been unintentionally represented in the original doodle—a strand folding back on itself, base-pairing to form obstinate structures that can actually prevent the reading and translation of the code by cellular enzymes. In addition, synthesizing custom-coded RNA strands was much more difficult than synthesizing DNA strands, so part of the time, Khorana cleverly synthesized DNA strands and allowed the cellular enzymes to make the RNA strands for him.
You can explore how to decode the genetic code yourself using our DNA/RNA simulator!* How would you determine the number of bases (letters) in each DNA word? You can design DNA and RNA sequences that clearly answer this question, and then move on to figuring out how to use your own sequences to reveal the code.
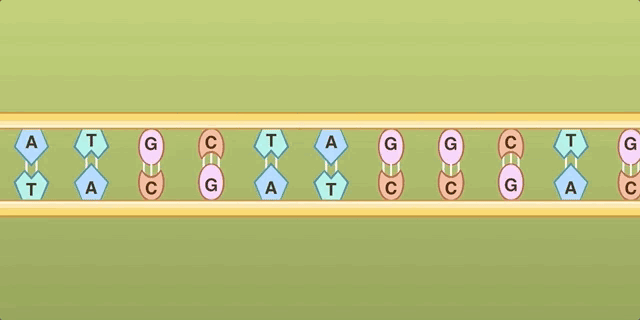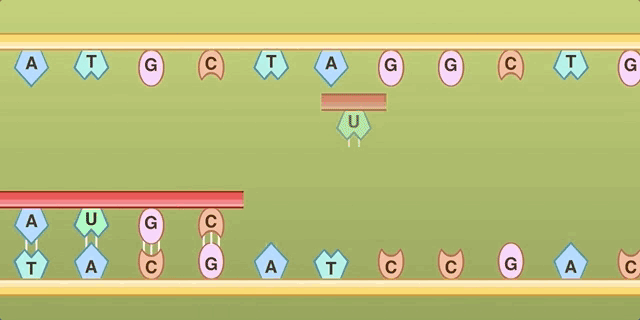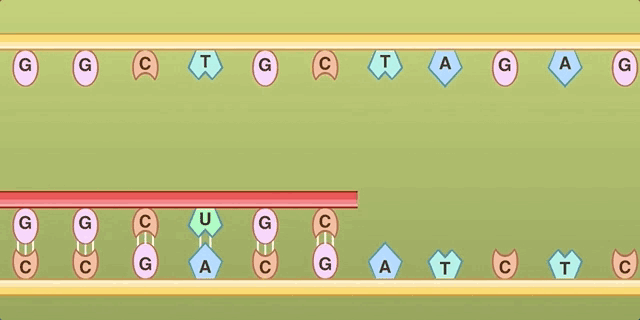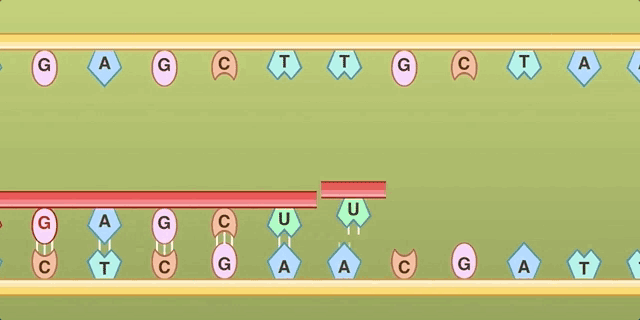

The process of transcription. Note that only the red RNA strand includes “U” for Uracil, so the original Doodle’s labels didn’t make sense.
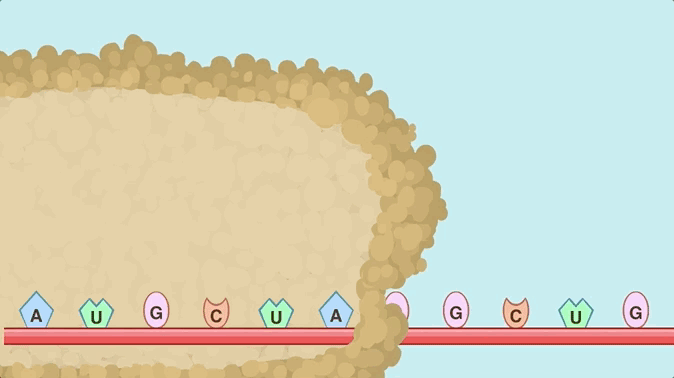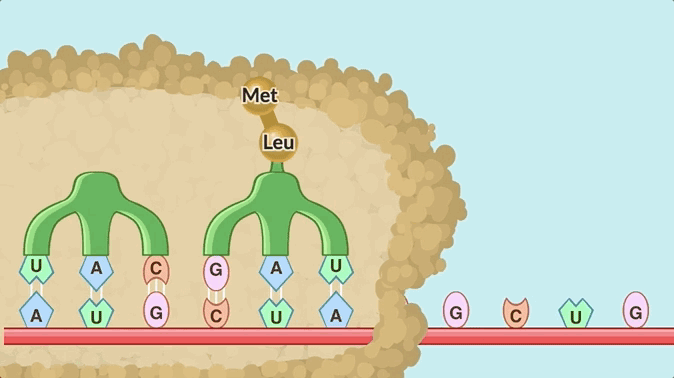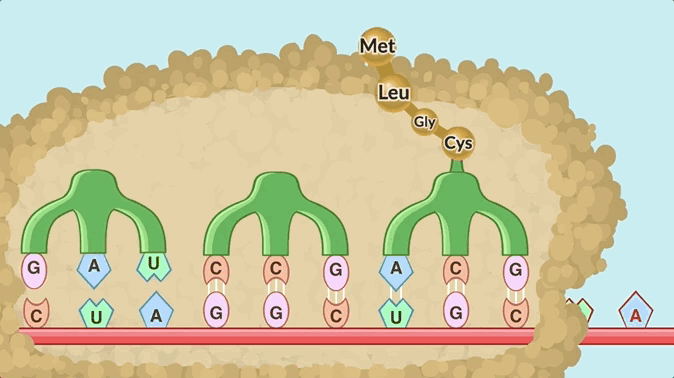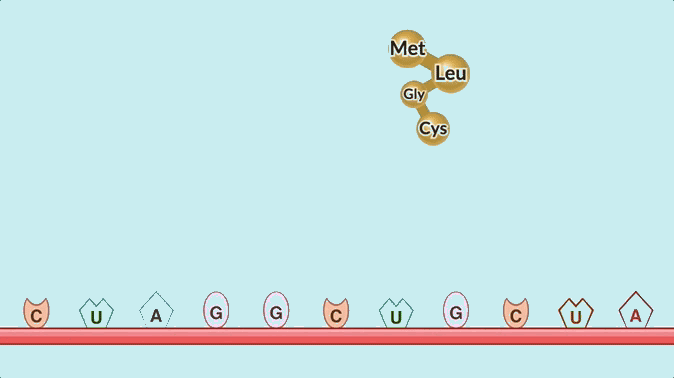

The process of translation. Here, the top base pairs are passed in by tRNA, and don’t form a strand at all, so this doesn’t match the original Doodle either.
* This Next-Generation Molecular Workbench model was developed thanks to a generous grant from Google.org.
2 thoughts on “An Edited Google Doodle and a Genetics Mini-Mystery”
Comments are closed.
I saw another Google doodle using four colors to represent the four DNA bases. It failed to pair the colors consistently!
Did you see it?
No, we missed that one!