Julia LaCava was a summer intern at the Concord Consortium. A junior at Ithaca College, she majors in communications.
The Automated Scoring for Argumentation project, which we affectionately called “HASBot” is wrapping up. This four-year partnership between the High-Adventure Science (HAS) team at the Concord Consortium and Educational Testing Service (ETS) was funded by the National Science Foundation to investigate the effect of automated scores and feedback on students’ content learning and argumentation skills.
HASBot is named after the robot avatar that uses an automated text-scoring program to provide real-time feedback to students on their open-ended written scientific arguments. Powered by the natural language processing tool c-raterML™ developed by ETS, HASBot is embedded in two High-Adventure Science modules.
We set out to research how students’ utilization of HASBot feedback impacted their ability to write uncertainty‐infused scientific arguments about groundwater systems and climate change. We wanted to see if and how students used the feedback to revise their responses to prompts embedded within the online curriculum modules.
Feedback is important to students, and research demonstrates that they benefit more from immediate and task‐specific feedback, rather than waiting for a teacher to read the response and write feedback, for example. HASBot automatically scores students’ text responses to their open-ended scientific explanations as well as their uncertainty explanations. Scores are based on scoring rubric levels.
HASBot feedback consists of a number on a score bar and a written statement. An arrow on the score bar indicates the machine score with a statement about what this score level represents while the text part of the feedback suggests what students should consider in order to improve their argument.
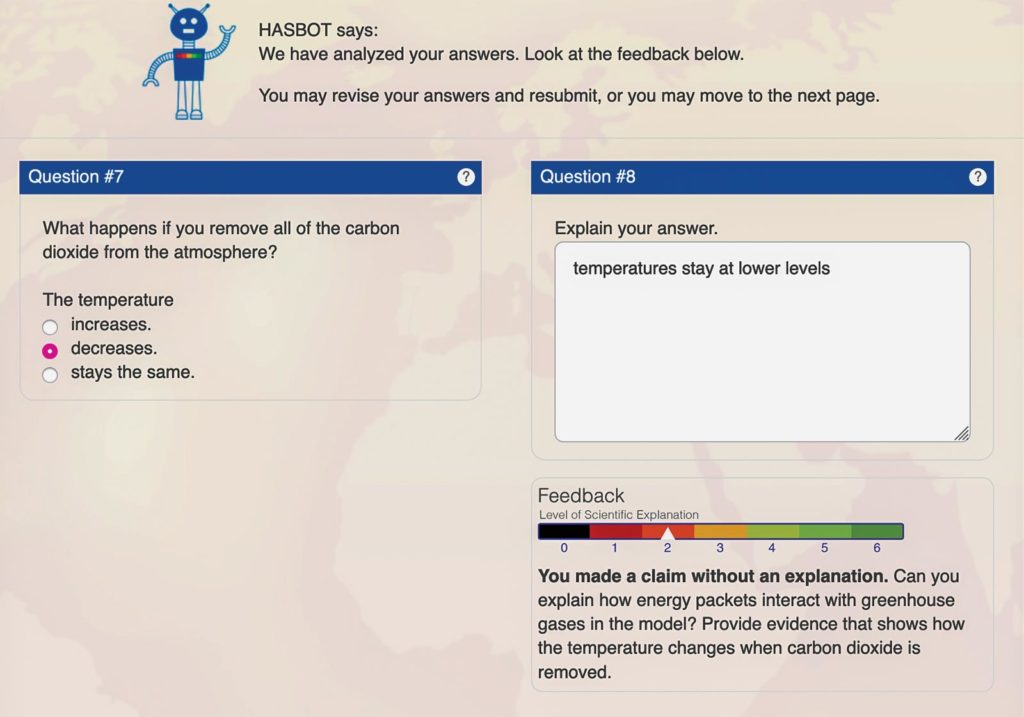
The video demonstration below shows one argumentation task in the freshwater module and HASBot in use. The user first submits a response to a question and gets feedback from HASBot. Notice how when the user revises their response, their level of scientific explanation on the rainbow meter increases.
Our latest analysis, published in Science Education, focused on the High-Adventure Science module “Will there be enough fresh water?” and highlights the importance of this new type of tool.
Our results show that the automated scoring of scientific arguments is beneficial and can improve student responses. Students achieved significant gains from pre-test to post-test on scientific argumentation (effect size = 1.38 SD, p < 0.001) consisting of claims, explanations, uncertainty rating, and uncertainty attribution. Students who completed all eight argumentation tasks had an average 2.12 point increase on their responses over those who did not, indicating the importance of students engaging with the module and argumentation. (This result is rarely achieved in educational innovations!) Teachers can use these results to support students’ consideration of the strengths and limitations of data and models and the uncertainty of the science itself.
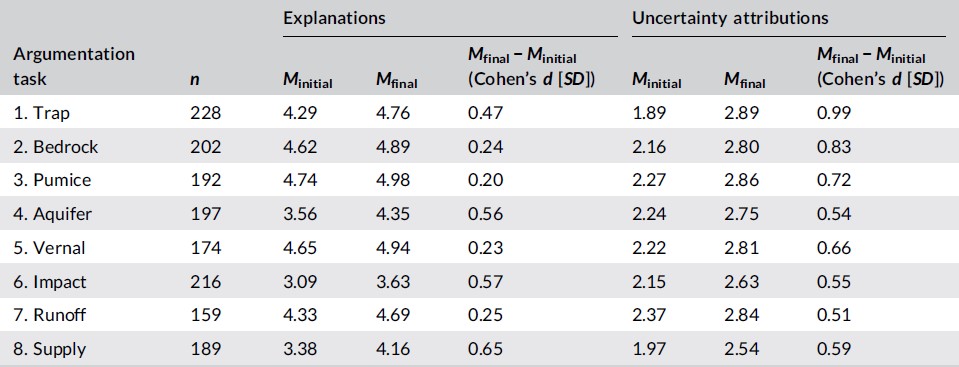
Improvements in explanations and uncertainty attributions after revisions
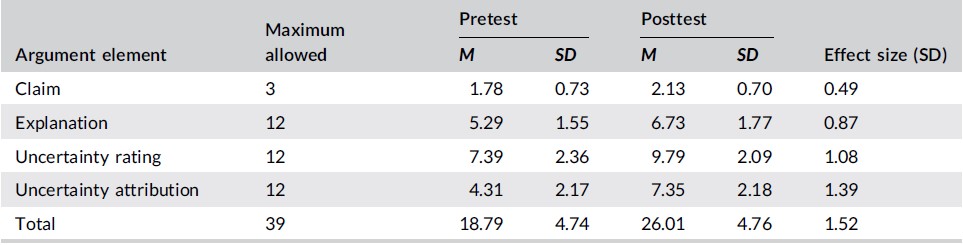
Student pre–post test gains in uncertainty‐infused scientific argumentation*
*Effect size represents Cohen’s d (mean difference divided by pooled standard deviation [SD]) represented in SD units. p Values for effect size were obtained from paired sample t-tests results: *p < 0.05; **p < 0.01; p < 0.001
As with any tool, though, HASBot has its strengths and limitations. Students were excited to receive a response from HASBot. The feedback helped students frame their reasons for uncertainty, an important factor as students rarely consider uncertainty in science classes. Though most students were helped by feedback, some had difficulty understanding the statements HASBot provided. We also saw that if the feedback was higher than it should have been, due to an error by HASBot, students were less likely to revise their answers.
Read more about our HASBot results over the years of our project:
- Automated text scoring and real‐time adjustable feedback
- Impact of automated feedback on students’ scientific argumentation
- Automated scoring assessment of students’ scientific argumentation on climate change
- How to support secondary school students’ consideration of uncertainty in scientific argument writing: A case study of a High-Adventure Science curriculum module