Under the Hood: Sensemaking Rubrics for AI
The challenge is how to get the right heuristic to the right student at the right moment. For teachers, helping students understand course content and identify their own progress within a sensemaking rubric is the challenge. MODS leverages machine learning to help teachers and students by using pattern recognition.
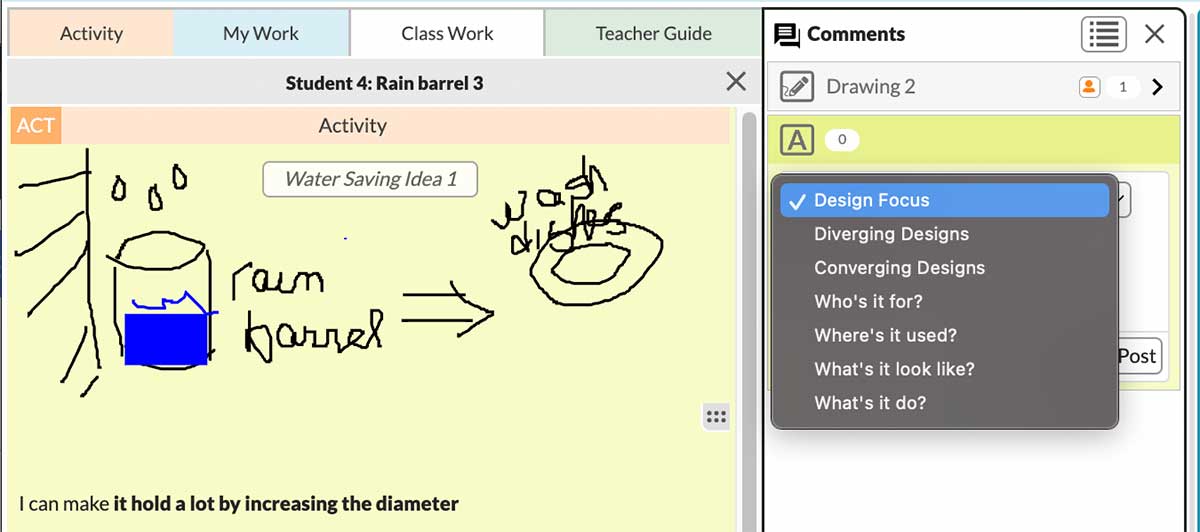
Machine learning, a specific branch of artificial intelligence, is a statistical system that finds patterns in human-readable work and identifies (or generates) those patterns in new work. Example documents that represent a pattern are first “tagged” by experts to identify important features, for example, the students’ “converging design” idea in the rain barrel example above. Over time, as more examples are tagged, the system “learns” to recognize those patterns in untagged examples. And as long as the system has enough examples in each category to be able to distinguish them, there’s no need to identify exact features that make an example fit one part of the rubric versus another. The most important part of the rubric application process is that it is consistently applied over lots and lots of example data.
Because sensemaking rubrics are unique to each discipline, we need subject matter experts on the new curriculum. A generic large language model such as ChatGPT would need this specialized training to work in this case. Participating MODS engineering and Earth science teachers who are familiar with the content score student work against the rubric. To streamline this task, we added a set of rubric tags (e.g., diverging designs, converging designs, etc.) to the comments section of our Collaborative Learning User Environment (CLUE) platform (Figure 1). Teachers select part of a student’s design document (e.g., a particular sketch) or the whole document and add a tag to it (Figure 2).
"config":{
"showCommentTag": true,
"commentTags": {
"diverging": "Diverging Designs",
"converging": "Converging Designs",
"user": "Who's it for?",
"environment": "Where's it used?",
"form": "What's it look like?",
"function": "What's it do?"
},
"tagPrompt": "Design Focus", ...
}
The CLUE web-based platform supports a broad array of digital artifact generation (e.g., text, drawings, tables), and includes a robust action-logging system for tracking student use of the platform. This makes it an ideal system for AI data mining because all tagging, history, and content is digitized in a format the computer can search. This also allows us to get rubric training from the humans who know students best—their teachers.
Students’ tagged work is sorted into the rubric categories, grouped alongside other student work. Since there are few wrong answers in a design engineering class, these groupings are not concerned with any notion of a “correct” response. Instead, they are designed to help students articulate the sensemaking stages within the class and to locate their own position within those stages. By introducing students to a rubric for contextualizing their work and helping them recognize those contexts in their own or their peers’ work, we hope to encourage them to be more engaged and motivated learners. Over time, the automated system will be able to categorize future work and achieve the holy grail of AI for engineering design—recommending new design heuristics to students.
Leslie Bondaryk (lbondaryk@concord.org) is the Chief Technology Officer.
This material is based upon work supported by the National Science Foundation under Grant No. DRL-2201215. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.