Exploring Artificial Intelligence with StoryQ
Mia submitted her college applications—six schools carefully chosen with the help of her guidance counselor. Now the anxious waiting begins. But when an article on Artificial Intelligence (AI) catches her attention, her anxiety increases. She learns that some colleges are considering the benefits and risks of using AI systems to improve the admission process. Mia’s college essay might be “read” by AI instead of humans. The thought of a heartless machine scanning her work gives her chills. Will her chance to get into her dream college be influenced by an AI model that predicts her likelihood to be a successful student?
Our Narrative Modeling with StoryQ project is creating tools, materials, and opportunities for young people like Mia to gain a fundamental understanding of AI as well as become a powerful voice in a society being rapidly reshaped by AI technologies. In this article, we walk through how a simple AI system works and how it is built.
Clickbait filter
Nowadays, we read most news on the Internet because it’s convenient and has a wide coverage. But some headlines—called clickbait—are designed to entice us to click for content that is useless, deceptive, or misleading. Imagine if we could design an AI filter to detect and potentially remove clickbait from view. The key ingredient is a training dataset that includes a large number of examples of headlines labeled by humans as clickbait or non-clickbait (Figure 1).
| # | Headlines | Labels |
|---|---|---|
| 1 | Can you match the actor to their animated film roles? | Clickbait |
| 2 | Covid in the Northeast | Non-clickbait |
| 3 | 32 gift ideas for the Canadian in your life | Clickbait |
| 4 | Space Shuttle Discovery back in Florida | Non-clickbait |
| (996 more rows) | ||
In our StoryQ app, developed as a plugin for our Common Online Data Analysis Platform (CODAP), we can extract many unique words from the headlines and transform the headlines into lists of words organized in a feature table (Figure 2).
| # | “you” | “the” | “in” | (394 more columns) | Labels |
|---|---|---|---|---|---|
| 1 | ✓ | ✓ | – – – – | Clickbait | |
| 2 | ✓ | ✓ | – – – – | Non-clickbait | |
| 3 | ✓ | ✓ | – – – – | Clickbait | |
| 4 | ✓ | – – – – | Non-clickbait | ||
| (996 more rows) | |||||
When we run this feature table through a machine learning program, the program discovers the rules of how these words are related to the labels and encapsulates these rules in a model. With this very basic approach, the model correctly predicts the labels for almost 90% of headlines. The approach is by no means state of the art, but it helps us see the inner workings of AI systems. But before we look at how the model works, it’s useful to reflect on how our brains work.
Consider this headline: The Struggles of Being a Sleepwalker. Curious? Want to know more? Tempted to click on it?
You are not alone! Most people are intrigued by the chance to peek into this unusual syndrome. However, the headline’s hyperlink leads to a distasteful short video surrounded by a blanket of advertisements and more clickbait—exactly what the headline was designed to accomplish.
What makes us take the bait? The words “struggles” and “sleepwalker” bring to mind a topic that we know a little bit about and are interested in learning more. The content words do the “baiting” to our human brain.
Does the model work the same way? Yes and no. While the model correctly labels it as clickbait, the words “struggles” and “sleepwalker” are completely irrelevant. In fact, they are not even in the model. What matters are the words “the,” “of,” and “being,” which are function words absent of any content.
The following annotated version is similar to what the model “sees.” The grayed-out words are ignored because they are not part of the model at all. The model only knows the underlined words, the so-called features, and uses them to make the prediction.
The Struggles of Being a Sleepwalker
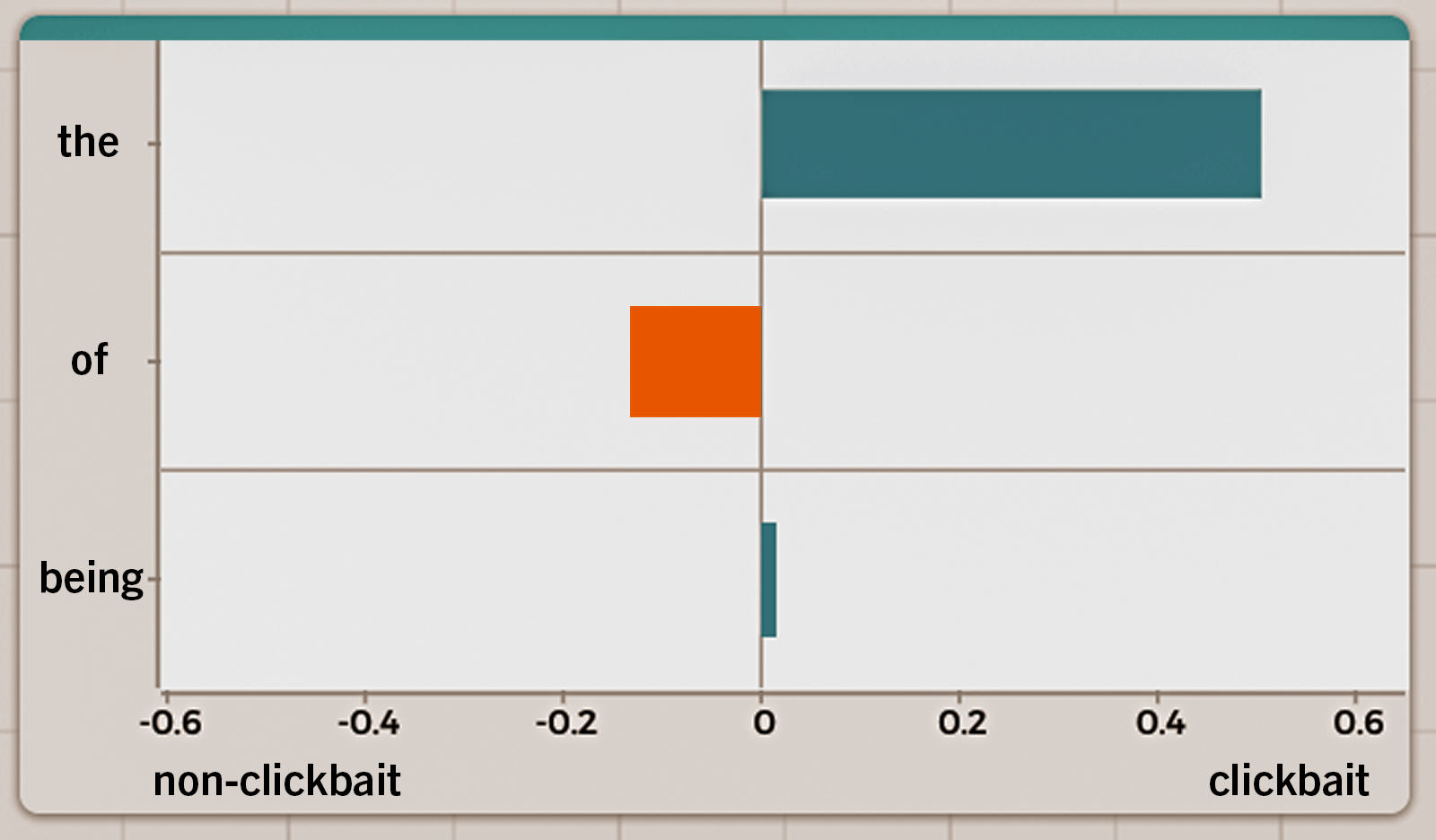
For each feature, the model has learned from numerous examples how strongly it is associated with clickbait while considering the presence of other features. This relationship is captured as a numeric value called weight. The word “the” has a weight of 0.505, which is a fairly large positive weight, given that the weights of all features range from -0.636 to 0.952. The word “of” has a small negative weight of -0.133. “Being” is almost neutral, with a weight of 0.003. The three features and their weights, summarized in Table 1, are all the model knows about the headline.
| Features | Weights |
|---|---|
| the | 0.505 |
| of | -0.133 |
| being | 0.003 |
With such seemingly limited information, how does the model use these features to make a prediction? Consider a bar graph where bar lengths represent the feature weights (Figure 3). Blue bars are the features pulling to the clickbait side and the orange bar pulls to the non-clickbait side. On average, there is a strong pull to the clickbait side.
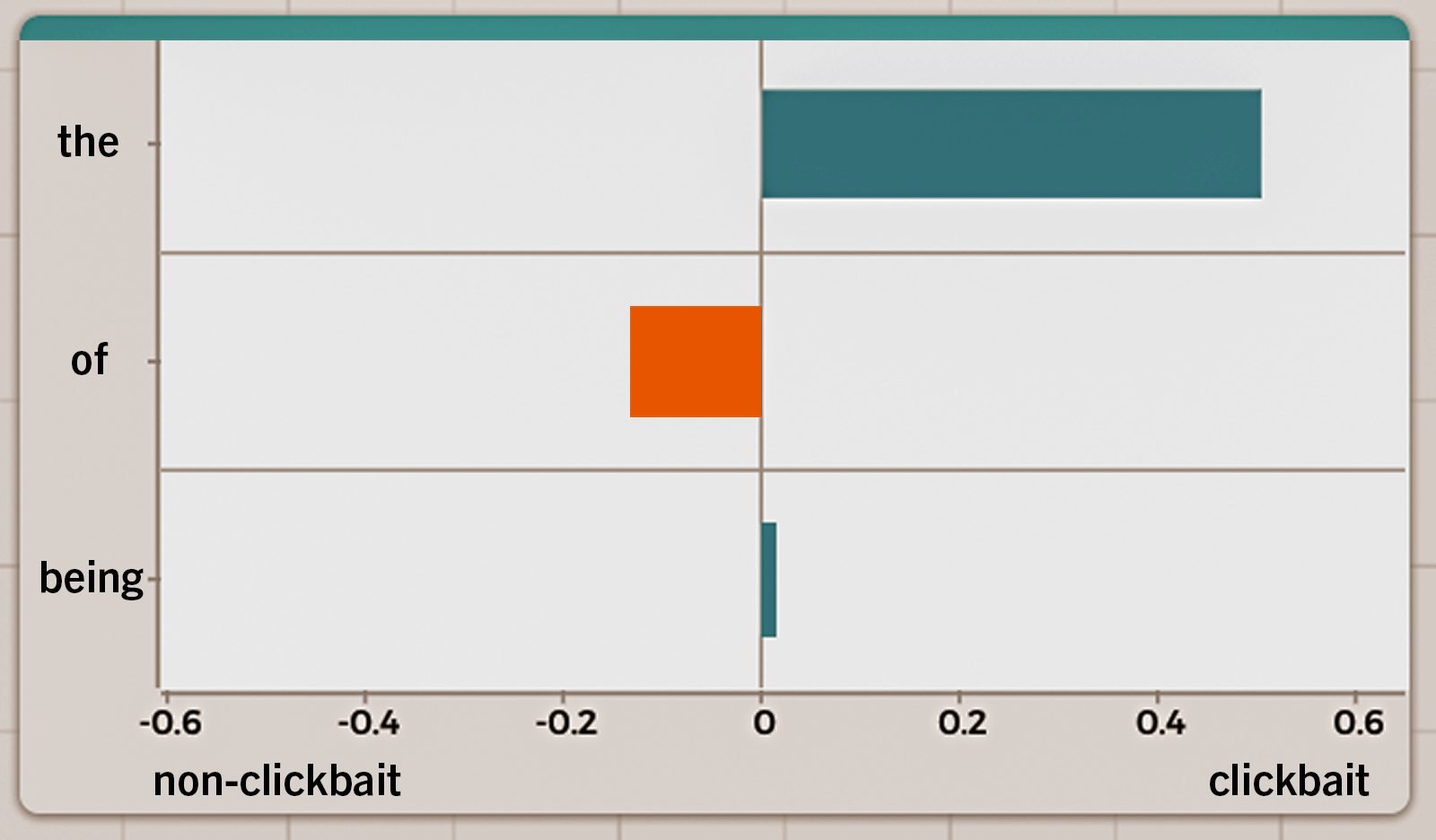
The model goes through similar reasoning by plugging the numbers into a formula, computing the probability of the headline being clickbait, and labeling it as clickbait based on a predefined probability threshold.* Counterintuitive as it can be, this is how the model predicts clickbait, sometimes using contentless words.
How did the machine learn?
The intriguing thing is how the machine learned this trick. Why do contentless words like “the” help predict clickbait? Recall that the machine learning program ran through the feature table and computed a weight for each feature. On the surface, the model just looks like a list of features, each with a weight (Table 1).
How does this simple list capture the rich meaning in the data? To get some insight into this question, we need to look at the features in context. For example, the word “the” seems to be a neutral word—we use it to make grammatically correct sentences. Surprisingly, in the clickbait model, the word “the” carries a large positive weight, making a headline much more likely to be clickbait if it contains this word. Why does a contentless word indicate the likelihood of clickbait? Let’s look at a few examples:
How well do you actually know the Addams family?
How well do you remember Season 5 of the Walking Dead?
Can you identify the Janet Jackson music video from a single screengrab?
Notice that what follows “the” are popular culture topics, such as TV shows and celebrities, which are very common in clickbait.
Let’s look at a few more:
18 times Squidward perfectly captured the dating struggle
40 country songs that defined your life in the early 2000’s
The recession may be a boon to book sales
Look around the word “the.” Most people are familiar with “dating struggle,” “early 2000’s,” and “recession” as common social phenomena. One final set of headlines:
The hardest Thanksgiving poll you will ever take
We know which celebrity you dislike the most based on your zodiac sign
The toughest Dragon Ball A quiz you’ll ever take
It’s not difficult to notice the exaggeration of “hardest,” “most,” and “toughest,” typical in clickbait. According to English grammar, such adjectives must be preceded with “the.”
So, does “the” capture any meaning? The answer is no if we consider the word by itself. But if we look at why it is used in certain contexts and what meanings it is associated with, the answer is yes. In these cases, the ties between “the” and popular culture topics, social phenomena, or comparative words come from grammatical rules in English.
Many features, especially those carrying large positive or negative features, capture meanings beyond their own definition and have more to do with clickbait as a special genre. For instance, “you” is a strong clickbait feature, frequently used to convey an invitation or imperative to the reader. The word “are” is also a strong indicator frequently used before adjectives or to create questions, which are common styles for clickbait. Numbers are also common clickbait indicators used in listicle headlines. While a computer model does not feel enticed or curious as we humans would, it can “know” what each feature signals about the mechanism underlying our perceptions.
Exploring AI with StoryQ
In real practice, AI systems are far more sophisticated, though they are developed in much the same way. Mia may not feel better about the college admission process knowing how AI systems are created, but we hope such background emboldens her to question the appropriateness of the AI applications she encounters in her life. StoryQ is designed to help students learn about AI’s power and its fallibility.
Q&A with Carolyn Rosé, Ph.D.
Carolyn Rosé is a Professor of Language Technologies and Human-Computer Interaction at Carnegie Mellon University, Interim Director of the Language Technologies Institute, and Co-Principal Investigator of the StoryQ project
What is the goal of the StoryQ project? And what is your role?
My Ph.D. students and I have taught the StoryQ team about text mining and we serve as curriculum advisors on the project. In addition to developing and researching curriculum for high school students, the goal of the StoryQ project is to help people think more critically about what they read regarding AI in the media. There’s a lot of unproductive hype and fear out there and we want students to know enough about AI that they neither believe the hype nor succumb to fear. Another goal is to help students envision future careers in AI. In our professional development trainings with teachers, we describe the programs at Carnegie Mellon and the different career paths possible for students.
How would you describe AI to a novice? What’s the difference between AI and machine learning?
The field of AI started around 1950 with an effort to get computers to behave in intelligent ways through reasoning that was automated. Machine learning is about pattern recognition and it’s based in the field of statistics. Machine learning is just one aspect of AI.
“Exploring Artificial Intelligence with StoryQ” posits the idea of a college admissions office utilizing AI. What would you say to Mia to make her less anxious about their use of AI?
I would tell her emphatically not to worry! It’s important to realize that admissions essays are a very different kind of writing. The College Board has used automated assessment on writing samples that are very topically focused and very narrow in terms of content, things you could build a model to make a prediction on. College essays are very broad and personal, and it’s not entirely clear what a college admissions committee wants to learn from them. If they were simply looking for “good writing,” I would trust a machine, which can check for grammar and well-formed sentences. This highlights an issue of AI in the media in general—people don’t see these distinctions. They don’t realize how the data and the nature of the judgment are different. Just because a feature got a high weight, that doesn’t mean it’s finding out what makes people click on clickbait.
So, are words like “the” and “of” actually indicators of clickbait?
I don’t think you can conclude that just because you know which things people clicked on that you are identifying what made people click. You’re probably identifying something that correlates with what made them click, and that might not even be in the writing at all. It might be an abstraction over the writing, but not in any individual word. So, if you represent the data in terms of features that are words, then you don’t have features to put weight on that are the real reason why somebody clicked on it. The word “the” is thus probably what we would call “misplaced weight.” It’s one existing feature that correlates with the real thing, which might not be anywhere in the feature space. The key point we want students to learn is that behavior that looks intelligent is not necessarily driven by a human kind of intelligence.
The article concludes that AI is both powerful and fallible. Where do you see its power and its failure?
Computer programs have the ability to process a lot of information very quickly. That seems very powerful. For instance, when you start typing in Gmail, it shows you what you might want to say next. That comes from a giant language model, but because people see that as a prediction about what they were thinking, they feel like it’s reading their mind. Humans are good at finding regularities, but not as good as computers. But humans can do creative problem solving way better.
How can a teacher use StoryQ?
We believe that feature engineering is a great fit for English Language Arts classes at the high school level. Students can learn about language constructs and what it is about language that makes it seductive or interesting.
You can try the curriculum at learn.concord.org/storyq
* The StoryQ app allows learners to train text classification models using the logistic regression model. When in use, the model computes the probability of a new headline being clickbait and labels it as clickbait if the probability exceeds 50%.
Jie Chao (jchao@concord.org) is a learning scientist.
This material is based upon work supported by the National Science Foundation under grant DRL-1949110. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.