The Bardic Bot: Integrating AI and ELA Education via Poetic Meter
From increasingly autonomous self-driving cars to climate change models, Artificial Intelligence (AI) has become a ubiquitous medium for understanding, explaining, and interacting with the world around us. However, opportunities to study AI at the pre-college level, if available at all, are limited to computer science classes. And yet many schools do not offer CS. This means that many students simply write off a future in AI because they aren’t “math people” or don’t think they can learn how to code. Our Narrative Modeling with StoryQ project aims to integrate AI into existing disciplinary studies such as English Language Arts (ELA) in order to prepare youth for the future.
Among many literary genres that students encounter in high school, poetry presents a unique opportunity for integrating AI education. Because public domain poetry texts are widely available and far shorter than novels, they make great candidates for introducing machine learning techniques in the ELA curriculum. In their 2016 paper for the International Conference on Computational Linguistics, Manex Agirrezabala, Iñaki Alegria, and Mans Hulden* apply Natural Language Processing (NLP) techniques to a selection of poetry in an attempt to identify its meter—the underlying rhythm expressed through stressed and unstressed syllables. They acknowledge that “while the rhythm in most line [sic] encountered in a work of poetry appears mundanely repetitive on the surface, poetry, while mostly a constrained literary form, is prone to unexpected deviations of such standard patterns.” It is this continual setup and subversion of literary expectations that makes meter an ideal playspace for machine learning and provides an opportunity to teach AI fundamentals in the English classroom.
Identifying iambic meter
We designed a weeklong StoryQ curriculum module around iambic meter, the metrical mainstay popularized by Shakespeare and reflective of natural speech patterns in English. Teaching meter to students is a complex process, especially when the goal is to develop competence in both writing and reading poetry. Students must develop a collection of related skills: identifying syllables in words, understanding and labeling different units of meter (e.g., feet and terms for line length), and connecting these patterns with the poem’s meaning. While building these skills can feel tedious and time-consuming, we believe that learning how to train machine learning models to identify the nuances of meter will engage students.
Explaining meter and scansion
In “The Bardic Bot: Training AI to Recognize Poetic Meters,” we first introduce essential concepts of meter and line scanning using a glossary of important terms, including meter, scansion, syllabification, and stressed and unstressed syllables. Students then identify the stress patterns of words as a group, and ultimately perform scansion on lines of poetry to identify its meter. They visit the University of Virginia’s For Better for Verse web-based learning tool to explore the meter of an entire poem, and receive automated feedback on their scansion and insight into how meter might affect the poem’s meaning (Figure 1).

Alien language activity
Once students become acquainted with meter, we turn to basic concepts of machine learning, again beginning with a glossary approach, reviewing terms like machine learning, artificial intelligence, feature, and target concept. To bridge the concepts of scansion with AI, we begin with an assignment that works with patterns of stressed and unstressed syllables rather than whole words to explore how a computer might identify patterns in meter without knowing the words intrinsically. Students are presented with the following scenario:
The people of Earth have been visited by an alien race! They seem to mean no harm, but humans have been unable to understand their language. However, it seems that they are a community of performers and artists because the words coming out of their mouths sound a lot like poetry. Specifically, there are patterns in their language that sound similar to the stressed and unstressed syllables in our own speech. Shakespeare’s Globe Theatre, the preservation society for William Shakespeare’s literature and legacy, has commissioned you to see just how “poetic” their speech really is. They want you to identify whether or not their language is in iambic pentameter as the ultimate test of their prosody.
Training the model using StoryQ
Students look at the stressed and unstressed syllables in the alien language and decide the likelihood that they are in iambic pentameter, comparing them to annotations we provide. Students consider how a computer might process this data, and teachers can scaffold the discussion with four features developed by the StoryQ team:
- Does the line have four to six iambs? Since the iamb (U/) is the fundamental unit for this target concept, this feature detects if it has a count that is within a range of five (hence, pentameter).
- Does the line have one or more anapests? An anapest (UU/) is one of the two three-syllable feet.
- Does the line have one or more dactyls? A dactyl (/UU) is the other three-syllable foot, arguably the least like an iamb.
- Does the line have two or more pyrrhics? A pyrrhic (UU) typically is relatively uncommon in formal poetry. Nevertheless, it is also counted here.
Because AI is fundamentally about computers finding patterns in data, students now develop and train a machine learning model in our StoryQ app, which is a plugin for our Common Online Data Analysis Platform (CODAP). They are given the scansion patterns and the above four features, and are walked through the basic steps of training and testing machine learning. The model then reviews each datum and labels each of the four features or “attributes” (columns in the data table) as true or false.
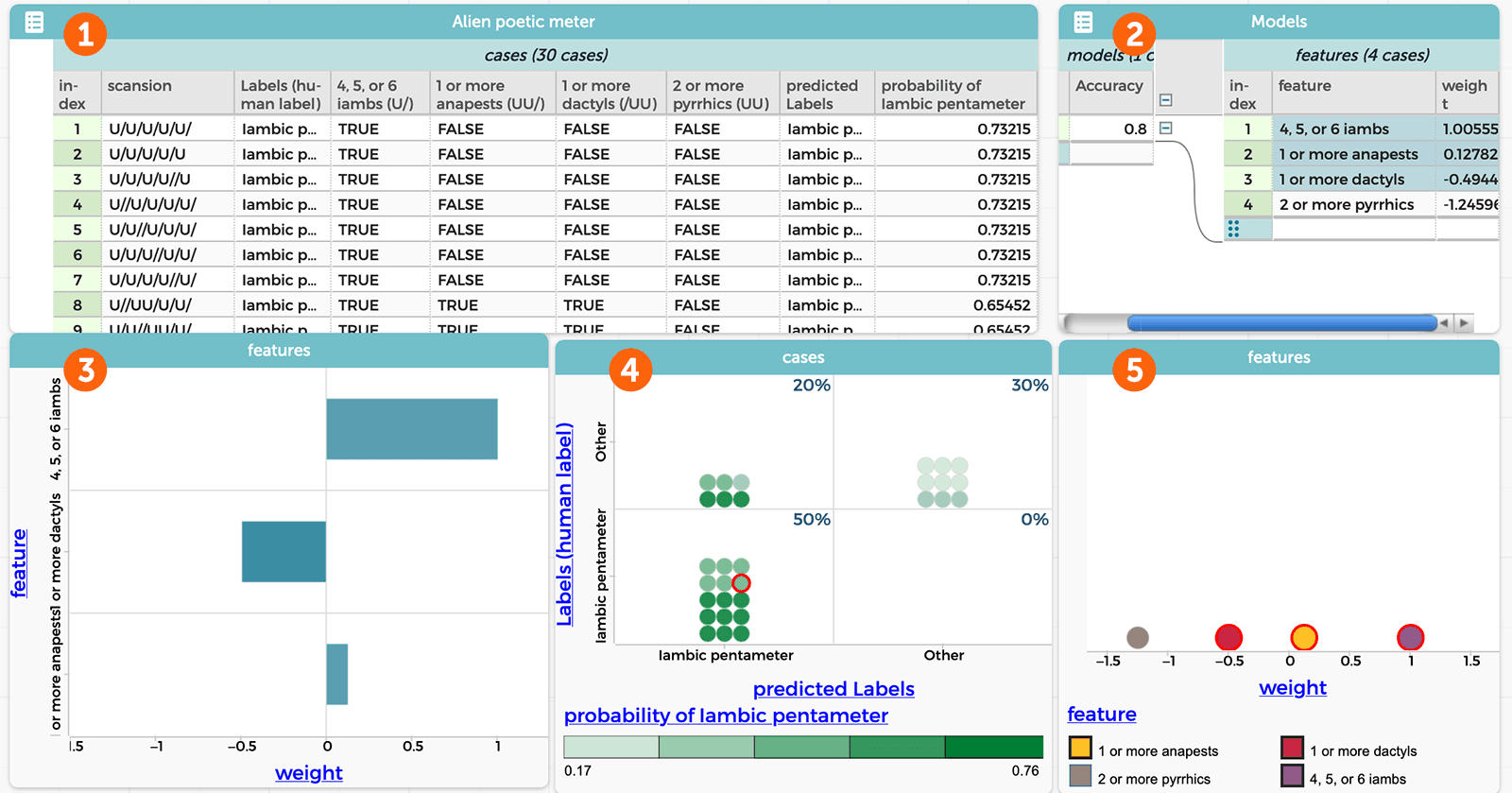
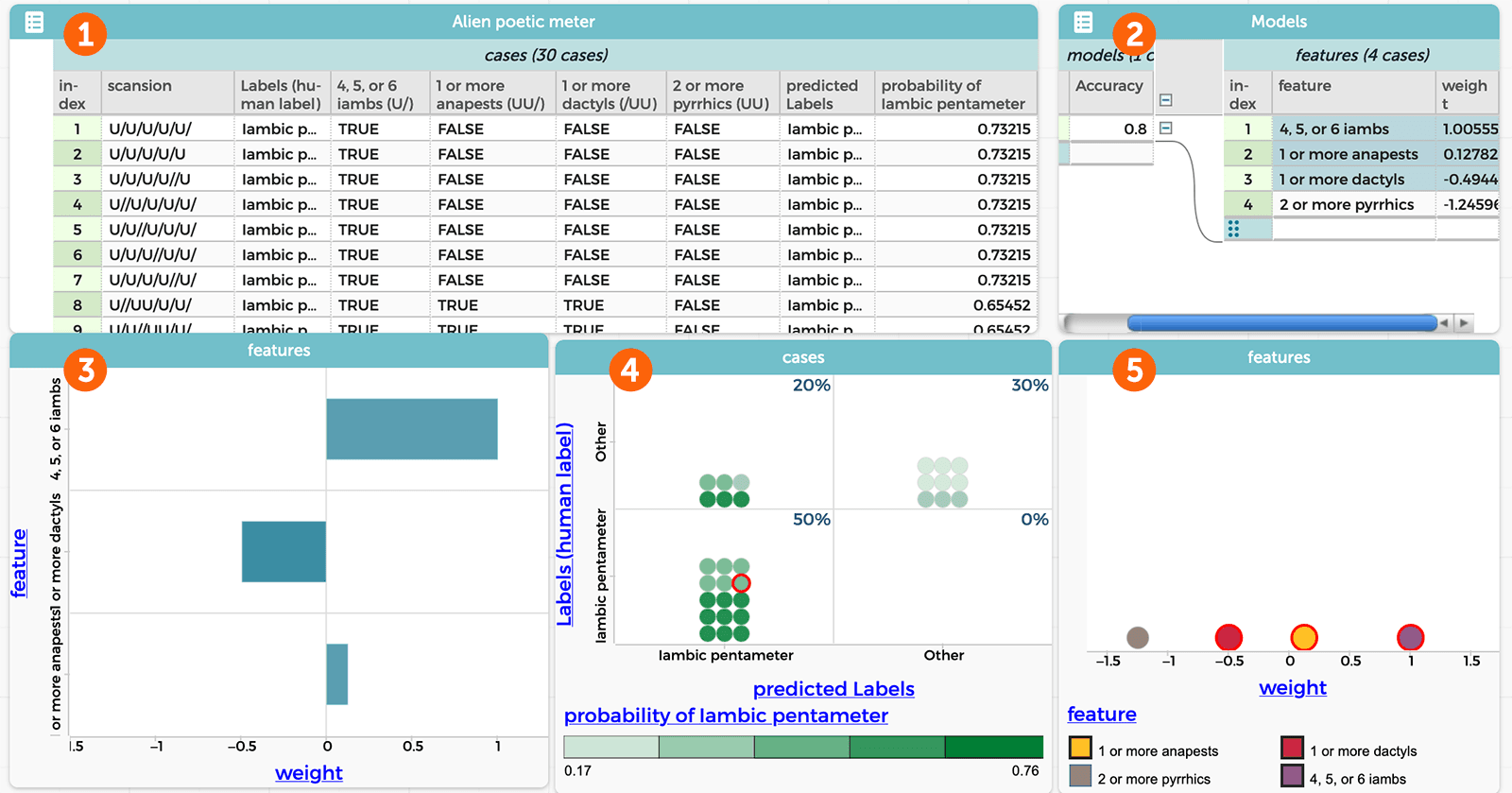
Using the StoryQ app, the model produces several visualizations (Figure 2). Panel 1 shows the original scansion data and the four features that are used to judge it, the true/false label that the model proposed for each datum, and the probability that datum is in iambic pentameter, which triggers the true/false label. Panel 2 displays the four features that make up the model and how strongly each figure might affect the true/false label (known as “weight”), which is also visualized by the scatter plot in panel 5. Panel 3 shows how the model applied a predictive label to a single datum (in this case, line 10 of the dataset in Panel 1) by showing the features and their given weights, which resulted in a “true” label (three of the four are shown; the fourth was also calculated, though cannot be seen here). Panel 4 shows a computation matrix, displaying what proportion of the data was correctly labeled. In this case, the accuracy was good, with 100% of the actual iambic pentameter lines labeled as such, and an overall model accuracy of 80%. This means that the chosen features could be useful. The teacher then challenges students to imagine other features that might also produce an accurate model like this one.
Conclusion
The Bardic Bot merges skill development in scansion and basic machine learning concepts and paves the way for further analysis on real lines of poetry using NLP. The goal of the curriculum is to scaffold text analytics for ELA students, so they learn to understand and appreciate both poetry and AI. We hope that students also learn that while machine learning is quite successful overall, at times it fails to scan the text correctly. Artificial intelligence is a powerful, if fallible, extension of human intelligence, rather than a replacement for it.
* Agirrezabal, M., Alegria, I., & Hulden, M. (2016, December). Machine learning for metrical analysis of English poetry. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (pp. 772-781).
Duncan Culbreth (culbreth.duncan@gmail.com) is a doctoral student in the Learning
Design and Technology program at North Carolina State University.
Jie Chao (jchao@concord.org) is a learning scientist.
This material is based upon work supported by the National Science Foundation under grant DRL-1949110. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.