The Data Science Education Revolution
Life is particularly interesting these days, if you have an eye for data. While predictions about entering the “data deluge” began only a decade ago, the current situation makes those warnings seem almost quaint. Today, data does much more than help us interpret complicated scientific or engineering problems and define basic choices we make every day, it dictates decisions made for us by the myriad machines, software, and algorithms that pulse just behind the curtain of modern life. Living and working in a world with data at its core lends a new urgency to teaching and learning about the skills and concepts of data science.
Two years ago, we noted in these pages that educators had only begun to conceive of the possibilities increasingly easy access to data offer for teaching and learning. Those ideas continue to ring true now. Society has a pressing need to envision the novel ways data can empower education. Moreover, there is an urgent need for action. Virtually every significant problem—from combating global warming to feeding the growing population, reducing violence, and increasing equity—will need to be tackled by people with data science skills and understanding. Unfortunately, there are far too few such people.
At the Concord Consortium, we have begun the challenging work of helping to launch the new field of data science education. As we do, we advance the goal of determining how best to bring about effective learning with and about data. We have made notable progress defining the boundaries and essential elements of data science education and drafting the first sketches of pedagogical and technological roadmaps. More important and exciting work lies ahead.

Preparing the next generation of data scientists
It is increasingly clear that data science is a critical area of focus for the future. And if you’re a data scientist—or a company that needs one—that fact is evidenced by the competition (and pay) across industry. Data science has taken hold at the undergraduate and graduate levels, with data science institutes, departments, and courses materializing everywhere.
However, K-12 education is another matter entirely. Despite the fact that tomorrow’s data scientist is today’s fourth-grader, experiences with data are rare in today’s K-12 classrooms. The situation is not entirely bleak—an increased emphasis on data in both the Common Core State Standards for mathematics (CCSS) and the Next Generation Science Standards (NGSS) has helped usher in a recognition that this situation should change.
To launch K-12 classrooms along the data-rich path we desperately need we must provide more opportunities for K-12 students to work with data in ways that will better prepare them for learning and doing data science in college and the workforce. We must focus on early experiences to ensure that children develop core ways of thinking about data: the habit of looking for the data in any given situation; the intuition that visualizing data lends important insight; and the instinct to reach for appropriate technological tools to aid analysis and visualization. Such habits of mind are essential to providing the foundation our future citizens need to live and work fluently in a data-filled world. However, they can’t just be tacked on after the fact—habits of mind become most potent when begun early in life and cultivated over time.
If today’s students are to be the ones who discover the data-driven solutions to important, complex problems of tomorrow, we must ensure that they have rich, immersive experiences with data throughout their pre-college learning, building up data habits of mind through frequent opportunities. Fortunately, there are useful points of entry into this important endeavor. The CCSS and NGSS provide good starting places for integrating data science skills and concepts into math and science learning, and the social sciences as well.
Extending K-12 data science curricula
What can we do now to foster data habits of mind in today’s youth? The answer begins with learning experiences that engage students in high-quality, data-rich experiences rooted in existing standards and curricula. It continues beyond the basic standards, incorporating opportunities for data exploration, visualization, and analysis.

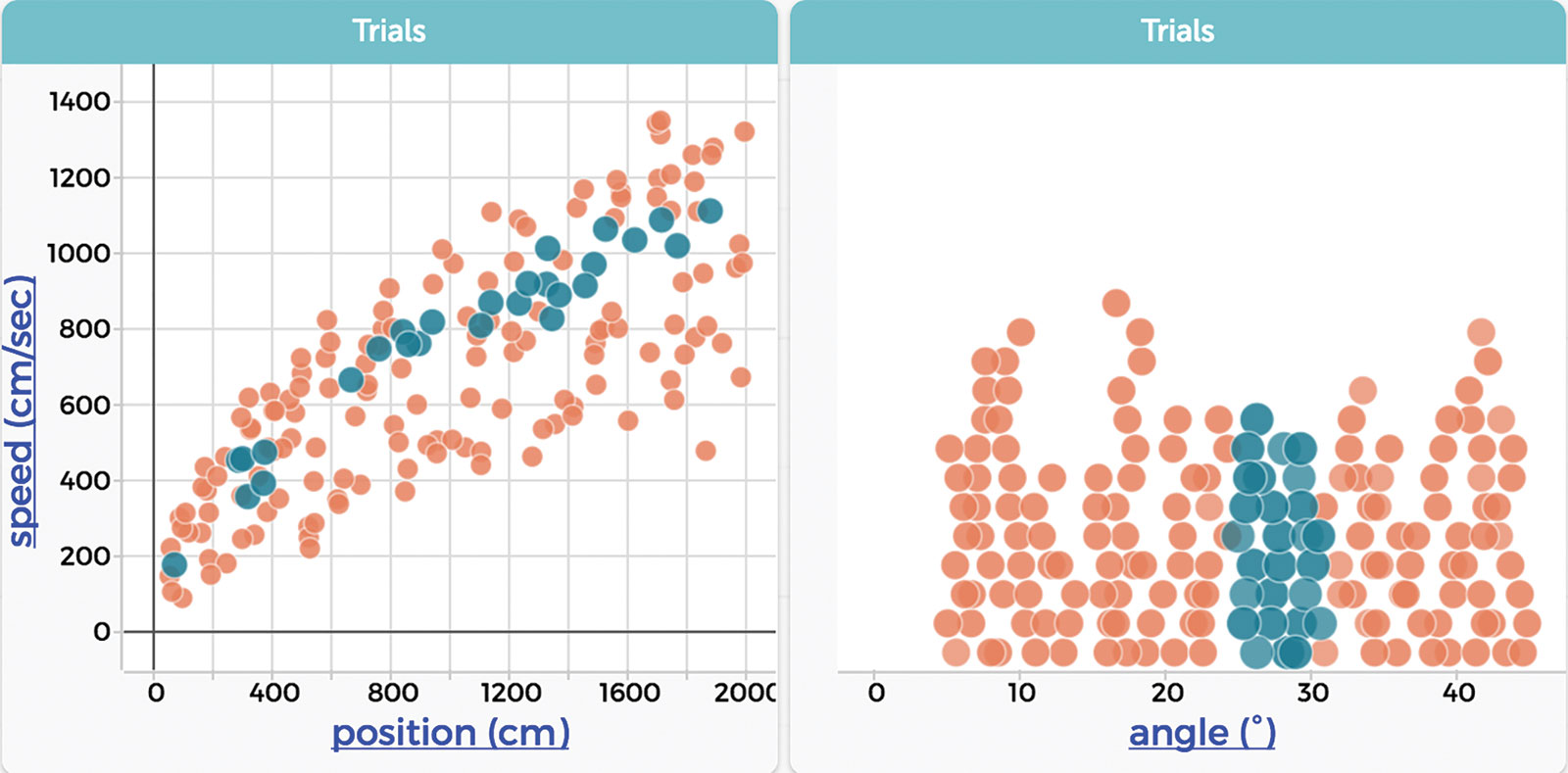
Tim Erickson gives a simple example familiar to every physics student: a ball rolling down a ramp. (See his blog post “Smelling Like Data Science.”) In current classrooms, students might work in groups to roll a cue ball down a ramp and analyze its motion, with all groups following precisely the same steps. How, he asks, could this same experiment incorporate data science? What if the students each did something different? If your answer is that the result would be a mess, you’re correct. The data set would require students to examine data from the motion of many different balls rolling down many ramps, of many different inclinations (Figure 1).
Consider the larger picture, however. What data is generated and analyzed in the two contrasting approaches? The standard lab activity yields a straightforward two-variable data set. The other yields a much larger data set with more than two variables. While both examples produce data that can lead to the lab’s targeted understanding, the second invites inquiry. Its messy data pose a puzzle, one which requires students to experiment. Students must try different ways of organizing the data and produce different visualizations in order to uncover the relationships within. In our job of preparing students to swim in the data deluge they are certain to encounter later in life, we must purposely prepare learners for roles where dealing with messy data will be not only necessary, but routine.
Let’s look at another example from a middle school science class. Using an agent-based simulation, students explore an ecosystem containing wolves, sheep, and grass. The simulation generates a lot of data for each run, and there are seven initial parameters to adjust, including how fast the grass grows. Even with identical parameters, two runs can differ greatly because of built-in randomness. After playing around for 20 minutes, students discuss their observations and questions, deciding to investigate “How can you set things up so that the wolves and sheep live happily together?”
One group focuses on the rate of grass growth (Figure 2). As they run the simulation multiple times, the students generate a large, varied, and naturally messy data set. They interact with the data by hiding some runs, reorganizing the data, and creating new groupings. Rather than see it as a barrier, they view the messiness as an invitation to dive in and poke around, coaxing out the stories hidden deep within the data.
These are the actions of future data scientists. As they work with the data, viewing and organizing it in evolving ways, students are performing the essential actions we call data moves. Building students’ experience, breadth, and fluency with such data moves is critical, because they are the raw material of data practices. Much of the data science done in the field involves these moves, wrangling, cleaning, and restructuring data sets so they can be further investigated. To prepare students for the future, we need curricula that evoke and encourage these data moves—at all levels and across all topics— in order to ensure that students develop coherent data practices and enduring data habits of mind.
Developing supporting technology
While curricula are essential to developing children’s habits of mind and fluency with data analysis, another necessary ingredient is technology designed for learning with data. Indeed, the tool students use to engage in rich data inquiry is the second make-or-break factor in the development of data science skills and understanding. Of course, such tools must be easy to use, but they must also draw learners into data experiences that are immersive and encourage exploration, experiences they will look forward to repeating with new data sets and new challenges.
Such data tools exist. The technology used in the two examples above is our Common Online Data Analysis Platform (CODAP). Designed specifically as a robust data exploration environment for education, CODAP is also easy to use—a 60-second demonstration launches students into hours of exploration. CODAP is highly interactive—students make their own choices and perform their own data moves, dragging and dropping data sets and variables in ways that illuminate and engage. CODAP works easily with web-based tools in ways that render it relevant to a wide variety of disciplines. And it’s free and open source.
Research
Curricula and data tools are essential for spurring the data science education revolution. But in order to build and design them effectively, we need significant research into how learners acquire data science skills, concepts, and habits of mind. Research findings can inform crucial design decisions in surprising ways. For example, the decision to use nested data structures in CODAP—a more useful way of structuring data than the flat, two-column approach encouraged by tools such as spreadsheets—is reinforced by our findings that younger students generated similar structures spontaneously. Research in a variety of areas will illuminate additional design principles and point to new curricular directions.
Defining future directions
To reach our goal of fostering data science education at all levels, we must answer important questions. What do lessons and curricula that effectively integrate learning data science into various disciplines look like? What do educators who wish to develop such materials need to know?
How do K-12 learners visualize data? What kinds of experiences improve their understanding of data? How can we coordinate across disciplines to maximize learning and leverage what students have learned in previous encounters with data? Answering these questions will require dedication, resolve, and commitment among a wide variety of partners. Curriculum developers, technology developers, researchers, policymakers, industry leaders, and more must coordinate their activity to bring about the needed changes. And the partnership doesn’t stop there—we invite you to join us as well! Visit concord.org/meetup to learn about upcoming data science education webinars and meetups, and to see how you can help bring about the data science education revolution.
Chad Dorsey (cdorsey@concord.org) is President of the Concord Consortium.
William Finzer (wfinzer@concord.org) directs the CODAP project.
This material is based upon work supported by the National Science Foundation under grant IIS-1530578. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.