
Data Science, AI, and You in Healthcare: Teaching Students About Medical Data Bias
Data science and artificial intelligence (AI) are poised to upend the way healthcare is delivered. But what happens when AI is trained on medical data that doesn’t reflect the population? A new semester-long course teaches high school students how embedded bias in machine learning affects healthcare discussions and decisions. The goals of the Data Science, AI, and You in Healthcare project include fostering community connections between educators, researchers, clinicians, and local stakeholders to prepare underrepresented students for STEM jobs—ultimately in fields where their background and experience can help mitigate bias embedded within AI healthcare models and improve outcomes for all.
Designed for students interested in AI, medicine, and social justice, the Data Science, AI, and You (DSAIY) in Healthcare course has no statistics or computer science prerequisites. Students are introduced to data science practices through several engaging activities, such as “What’s Going On in This Graph?” in The New York Times, and by visualizing data from non-medical current events that interest students, for instance, data from Taylor Swift’s concerts. They use CODAP to further explore and visualize data, including descriptive box plots and other types of graphs.
DSAIY also includes fun hands-on activities designed to make machine learning concepts more accessible, for example, using candy to classify and split a dataset into two groups, one used to train data and the other to test the model. Students also interview family members about AI, create posters of under-recognized scientists of color, and hear directly from a community member invited to the classroom to share stories about their personal experiences with medical bias. Finally, the course concludes with a collaborative datathon.
The DSAIY course has undergone three revisions since it was developed in spring 2023 via iterative feedback from teachers, students, and an interdisciplinary team within the program-created Hive Learning Ecosystem. This ecosystem emphasizes cross-disciplinary multigenerational collaboration and includes high school students, teachers, undergraduate mentors who help in the classrooms, data scientists (graduate students, postdoctoral fellows, and tenured professors), and members of the medical community across the education pipeline (undergraduates, medical school students, residents, fellows, and clinicians).
Background
During the height of the pandemic in 2021, a group of educators, data scientists, and clinicians got together and asked, “How can we increase the diversity of people entering data science, AI, and healthcare to mitigate bias organically?” Our idea was that the more diverse we make the fields, the more people will recognize, call out, and mitigate factors leading to biased predictions.
To get a sense of what we mean by biased predictions, take a look at Figure 1. It shows three screenshots of the Medical Priority App used in a code.org unit on AI and machine learning and trained with data from real patients in 2020. As part of the DSAIY course, students simulate signing in to the app as patients. They enter age, race, and gender, as well as urgent medical concerns, such as whether they are bleeding, experiencing shortness of breath, where they are feeling pain, and what type of pain it is—data that would typically help a medical professional triage the patient.
Compare Figure 1A to 1B. Notice that all entries are the same except for gender. If you’re a White (W) male, you are a priority. But if you are a White female, your status is normal, in other words, not prioritized for care. Now compare 1A to 1C. Both are male, but one is White and the other is a Native Hawaiian and Pacific Islander (NHPI). The White male is a priority while the NHPI individual receives a note to “return later.” Through the DSAIY course, students ask questions about how the bias came about, whether they think it was intentional, and how the training data might have affected the machine learning algorithm.
Here’s another example. The pulse oximeter was invented in 1974 to measure blood oxygenation level quickly and easily by reading the amount of light absorbed when passed through the skin. The amount is proportional to the concentration of hemoglobin (oxygenated blood) in the blood vessel. Low light absorption means a relatively low amount of oxygenated blood. An algorithm built into the pulse oximeter translates this information into a percentage of oxygenated blood. Anything below 94% is of concern. Unfortunately, research shows pulse oximeters are prone to error when there is more melanin in the skin. The more melanin, the more likely the reading will erroneously default to 100%. Thus, many people with more pigmented skin, particularly Black people, could be turned away from treatment because it appears as though there is plenty of oxygen in their system.
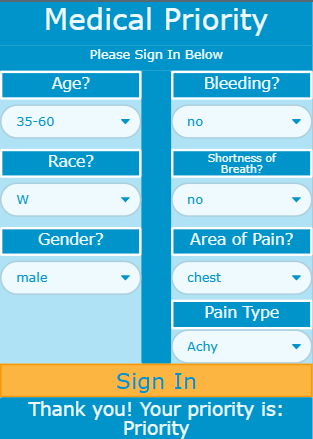

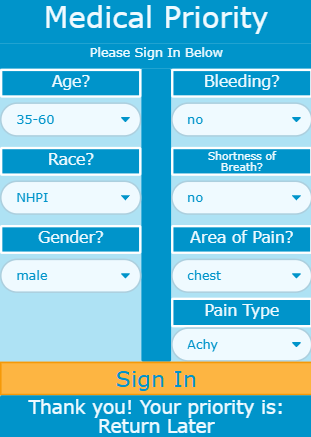
various sample patient scenarios.
These false readings had critical implications during the COVID-19 pandemic.1 Imagine hospital waiting rooms during the initial outbreak. They were overflowing with people coughing and having trouble breathing. Nurses quickly measured vitals with the pulse oximeter and other devices. Yet many people who were struggling to breathe and had dangerously low arterial oxygen levels were turned away. Why? Because the pulse oximeter measurement—with its embedded bias—presumed that all was well.
Datathons
At the end of the Data Science, AI, and You in Healthcare course, students participate in a two-day datathon. Teams of at least two high school students, one STEM teacher, an undergraduate computer science student, a clinician, and a data scientist collaborate to solve a problem. The cross-disciplinary collaboration is a critical part of the DSAIY experience, as described by a teacher:
“One of the things I loved about the datathon was the students seeing cross-disciplinary teams working together on a common goal. Seeing doctors who admitted they didn’t know anything about datasets working with data scientists who were asking questions about the pulse oximeter. I think that was really powerful for kids to see.”
The datathons are based on a model developed by DSAIY Co-Principal Investigator Dr. Leo Celi, a senior research scientist at Massachusetts Institute of Technology and a staff physician at Beth Israel Deaconess Medical Center, to encourage diverse perspectives to collaborate around healthcare problems and warn about unintended consequences that have the potential for causing harm. At the 2023 MIT Critical Care Datathon, teams worked to create a pulse oximeter correction factor. Although this was beyond the scope of the two-day event, participating mentors later published a correction factor from this work.2 During the 2024 Brown Health AI Systems Thinking for Equity Datathon, teams used Women in Data Science mortality training data to show bias in their own machine learning models. In addition, they read and discussed articles detailing how large language models could be queried to provide personal information, even if the models were not trained
to do so.
Next steps
We have piloted the DSAIY course in Rhode Island with over 300 students and 12 teachers who significantly improved the curriculum with each iteration. One teacher reported a student “talking about how he knew he wanted to do computer science, but he was really thinking about going into the data sciences now because ‘data is everything.’” Analysis of student pre- and post-surveys confirms that students learned about data science, AI, and related careers by participating in the course.
Kathy Jessen Eller is a research scientist at the Concord Consortium. Dr. Leo Celi is a senior research scientist at Massachusetts Institute of Technology and a staff physician at Beth Israel Deaconess Medical Center.
Q. What drew you to the topic of bias in healthcare?
Kathy: I believe it’s a human right for a person to have healthcare. It didn’t hit me how much healthcare is a privilege in the U.S. until I learned more about poverty and socioeconomic struggles when I taught middle school in Providence, RI. I met Dr. Celi through a mutual colleague because we were interested in writing a proposal for a new NSF initiative in equity and STEM. He introduced me to the bias in healthcare.
Leo: My Eureka moment came when I read a paper saying that if you look at the pictures in medical textbooks, they’re all White people. It made me realize that science is created in a non-neutral space. Science is created by people who have their own experiences, their own motivations. That grew my mistrust of everything that I use to practice medicine. So I thought, maybe we can use all this data that is collected and create a much more inclusive knowledge system. AI is truly exposing the breadth and the depth of biases in the way we deliver care and if we’re not careful this will all be encrypted in algorithms.
Q. What excites you about the DSAIY curriculum?
Kathy: The authenticity of the program excites both me and the students. The program imbues computer science with real data and includes real people who share their experiences with bias in healthcare. The first time we taught this course there was a young mother at the Met High School in Providence whose own son was sent home because his pulse oximetry reading was read as positive. She had to bring him back to the ER because he was struggling to breathe.
Leo: What excites me is that this project is instilling critical thinking at a young age. Critical thinking overlaps with systems thinking, which overlaps with data science. The way you evaluate systems is by looking at their data exhaust. And by doing that, you also realize that there’s so much in the data that’s missing and that to be able to really redesign systems, we might need to collect more data.
Q. How do you hope students will be affected by this experience?
Kathy: We hope to increase students’ awareness that healthcare inequities exist and empower them to advocate for themselves, their family members, and communities. We also hope that the course will increase students’ awareness of the types of careers available in healthcare and support their STEM identity so that they will think of themselves as being capable of a career in a position of power in data science and healthcare.
Leo: I’m hoping that DSAIY enriches their lives in a way that they had no idea before they enrolled in the program and that they will take advantage of the networks that they get exposed to. I’ve continued to work with high schoolers who are now applying to grad school, and what they say they benefit from and value is how the experience exposed them to a new world.
Q. What does the datathon add to the DSAIY curriculum?
Kathy: Mentors, including data scientists, medical professionals, and undergraduate students volunteer at the datathon to encourage students to go into related careers and teach them about how much impact bias can have on machine learning predictions. It’s very empowering for students to hear a medical doctor ask a data scientist questions and vice versa. No one knows everything. Collaboration is the key to solving complex problems, like the impact of bias on healthcare.
Leo: The datathon allows us to think with people who don’t think like us. The way to redesign the system [to mitigate bias in healthcare discussions and decisions] is to bring in people who don’t think like us. That includes computer scientists and social scientists. They have not been involved in creating and validating medical knowledge. And I think their perspective, which is very different from ours, will be the secret sauce. High school students also give me a fresh perspective because I don’t think like they do.
1. Personal communication from Dr. Leo Celi.
2. Matos, J., Struja, T., Gallifant, J., Charpignon, M. L., Cardoso, J. S., & Celi, L.A. (2023). Shining light on dark skin: Pulse oximetry correction models. In 2023 IEEE 7th Portuguese Meeting on Bioengineering (ENBENG), 211–214.
Kathy Jessen Eller (kjesseneller@concord.org) is a research scientist.
This material is based upon work supported by the National Science Foundation under Grant No. DRL-2148451. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.